图算法:Node2Vec
相关引用:
理解node2vec
node2vec在微信朋友圈 Lookalike 算法的应用
Complete guide to understanding Node2Vec algorithm
Node2Vec 遵循这样的直觉:图中的随机游走可以像语料库中的句子一样处理。图中的每个节点都被视为一个单独的单词,而随机游走被视为一个句子。
最近在工作中遇到了一个场景,在特征库中,有一维嵌套特征,由一系列的时序事件组成。这代表着一个样本会有多个不等长的时序事件,而每个事件拥有结构化的格式以及不同的事件分类。
对于这样的特征,此前的方法是对固定的类别进行时间上的差分统计,这样$n$种事件分类,$d$种时间差分次数下,会产生$n*d$维额外特征,例如近3天A事件触发次数,近5天B事件触发次数。
由于特征并不等长,而且随着时间的发展,这个时序特征里会出现一些未知的特征信息。例如,当新的推理集中出现了未知事件C,那么就无法处理这个新特征。当然,可以用一个未知变量来统一合并未知的事件,但是这会影响不同事件的分布比例。
另外的两个问题就是维度灾难和稀疏性,当有10个不同的事件类别时,取3,5,7天差分,就会有30维特征,扩大到20维时,就是60维特征。并且由于任务的性质,这60维特征里绝大多数都是0。成倍增加的稀疏特征需要庞大的数据集让模型拟合。
那有没有办法对他们进行嵌入呢?显然,每个样本都拥有一个不等长数组,这个数组不光体现了时序,还体现了样本对不同分类的偏好。既然正向的手动处理分类特征比较困难,那也可以反向从不同分类对样本的连接次数来构建图特征。
图嵌入也是经过长时间发展的算法之一,这次的主题是Node2vec,也是跟随着Word2vec出现的嵌入算法之一。
Node2vec与Word2vec
Node2vec与Word2vec两者的思想非常相似,都是希望通过构建序列,在训练中学习到不同item之间的共现关系。回顾一下Word2vec,它使用一个滑动窗口来滚动获取目标预测词和临近词。随后,词表中每个词进行one hot处理,得到一个索引表。
这里以Skip-Gram为例,我们在得到索引表后,开始训练。
我们拿“今天天气真好”作为训练语料,分词后得到今天,天气,真好三个词,即词表大小$V=3$,假设词向量维度:$d=4$。希望在给定中间词天气的情况下预测周围两个词。
用滑动窗口+window size=1构建训练语料:今天 → 天气,天气 → 今天,天气 → 真好,真好 → 天气。
进入输入层,Skip-Gram 采用独热编码作为输入。天气在词汇表中的索引是 1,其 one-hot 表示为:$x_{\text{天气}} = [0, 1, 0]$。
进入嵌入层,一个嵌入矩阵$W$(大小为 $V \times d = 3\times4$)转换成低维向量。输出$h = W^T \cdot x$
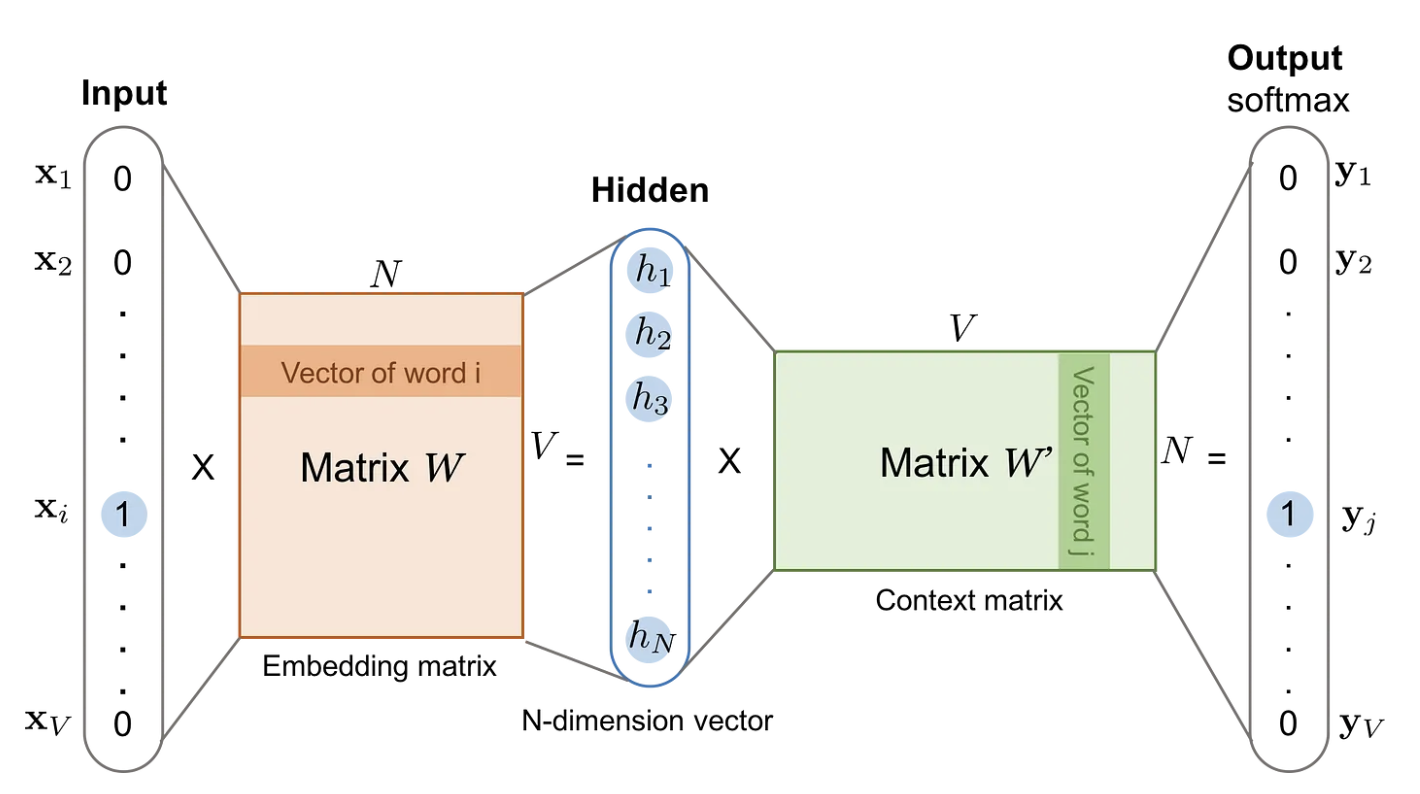
维度变化:
- 输入 $x$ 的维度:$V = 3$
- 经过嵌入矩阵 $W$:$(V, d) = (3, 4)$
- 输出$h$的维度:$d = 4$
进入输出层,用另一个矩阵 $W’$(大小为$d \times V$),用来计算预测概率,输出的结果用Softmax归一化。用交叉熵作为损失,反向传播,最后得到嵌入矩阵就是我们想要的嵌入表。单词乘嵌入矩阵时,就相当于取到对应维度的$1\times d$维的嵌入行向量。这就是为什么说,Embedding本质上就是查表。
Word2vec通过上下文的滑动窗口获得序列文本,这是它学习嵌入的方式。这样的思想被用在了很多地方,早在2014年,就出现了DeepWalk算法,给定一个节点,随机采样获得下一个节点,得到最终训练序列,然后同样用Skip-Gram来训练得到嵌入矩阵。两年后,Node2vec在此基础上进行了小幅度的改进。
随机游走
Graph Embedding本身值得探索的点不多,大多围绕如何构建序列展开,随机游走是其中的一大创新。
在图(Graph)结构中,随机游走是一种从一个节点出发,根据某种概率规则访问其邻居节点的过程。举个简单的例子: 假设我们有一个图:
1 | |
如果我们从节点 A 开始,每次等概率地选择一个邻居节点,我们可能得到以下路径:
1 | |
这个序列就是随机游走产生的路径(Walk)。
随机游走有两种类型,一种是在无权重时等概率,有权重时根据概率选择下一节点,另一种是偏置随机游走,通过偏好设置来选择深度优先(DFS-like)偏置或广度优先(BFS-like)偏置。前者让随机游走更多访问远程节点,后者优先访问临近节点。
Node2Vec 的创新点来自于偏置随机游走,引入了两个控制参数:
返回参数(Return Parameter,p):控制是否返回上一个访问的节点。$p$越大,随机游走越不容易返回上一个节点。
进出参数(In-out Parameter,q):控制 BFS 和 DFS 之间的平衡。 $q > 1$,倾向 BFS(局部游走),$q < 1$,倾向 DFS(深度探索)。
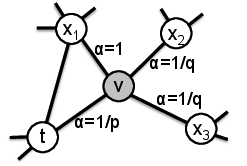
定义:转移下一节点的概率$\pi_{vx} = \alpha(t, x) \cdot w_{vx}$
其中:
- $w_{vx}$ 是图中边 $(v, x)$的权重(若是无权图,通常设为 1)。
- $\alpha(t, x)$是一个因子,它控制游走从前一个节点$t$到新节点$x$的偏好。
一阶随机游走只考虑下一节点的概率,Node2Vec考虑了二阶关系,因此用了两个参数来回溯之前的历史节点。
工业实现的难点
在写代码的时候意识到下面三个难点:
图算法通常都会面临内存不足的问题,尤其是在千万级别,临近节点和边都会达到百万甚至千万级别,需要的内存可能会达到上百G,这是难点一。
第二点则是统计特征,怎么将统计特征融入到Embedding中,工业推荐算法以前是采用类似于Wide&Deep的方法,统计特征和嵌入特征分开建模,结果进行合并。在后期,也有直接concat的处理,但是目前似乎没有一种公认有效的方法来统一处理它们。
权重公式如何计算?如何处理冷启动用户?
最后附上知乎相关问答:深度学习如何引入统计特征?
2025/3/1 于苏州