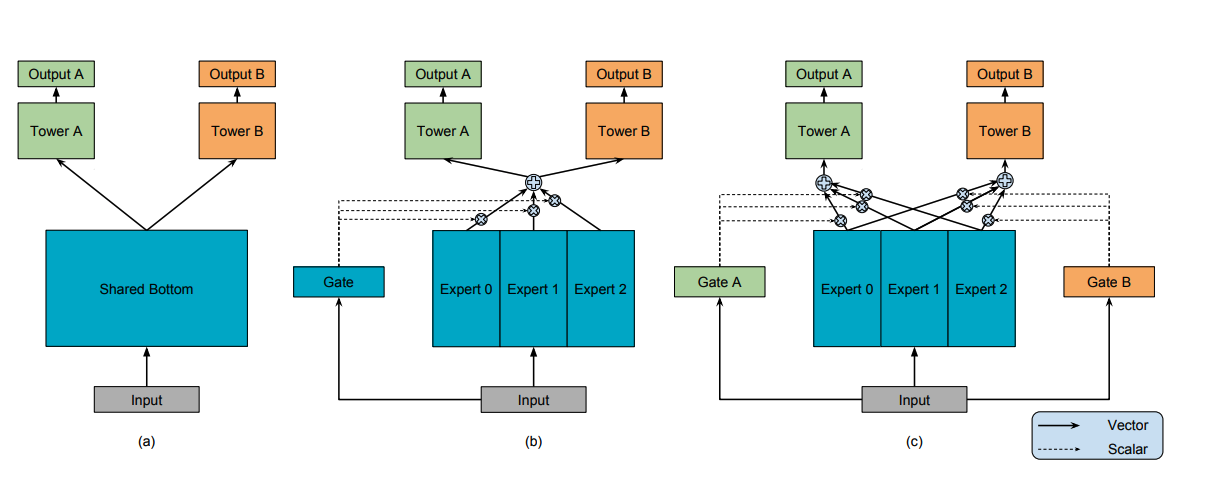
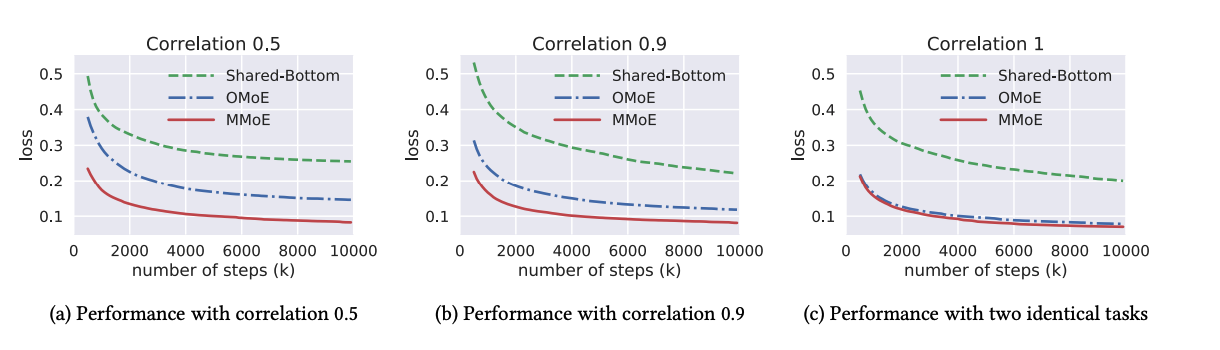
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
| import torch
import torch.nn as nn
from ..basemodel import BaseModel
from ...inputs import combined_dnn_input
from ...layers import DNN, PredictionLayer
class MMOE(BaseModel):
"""MMOE实现类
:param dnn_feature_columns: 用于模型中 DNN 部分的所有特征列的集合。
:param num_experts: 整数,专家网络的数量。
:param expert_dnn_hidden_units: 列表,表示每个专家 DNN 的层数和每层的神经元数量。
:param gate_dnn_hidden_units: 列表,表示每个门控网络 DNN 的层数和每层的神经元数量。
:param tower_dnn_hidden_units: 列表,表示每个任务塔 DNN 的层数和每层的神经元数量。
:param l2_reg_linear: float,线性部分的 L2 正则化强度。
:param l2_reg_embedding: float,嵌入向量的 L2 正则化强度。
:param l2_reg_dnn: float,DNN 部分的 L2 正则化强度。
:param init_std: float,用于初始化嵌入向量的标准差。
:param seed: int,随机种子。
:param dnn_dropout: float,[0,1) 范围内的值,表示 DNN 层的 dropout 比例。
:param dnn_activation: DNN 中使用的激活函数。
:param dnn_use_bn: bool,是否在激活函数前使用 BatchNormalization。
:param task_types: 每个任务的类型列表,``"binary"`` 表示二分类损失,``"regression"`` 表示回归损失。例如 ['binary', 'regression']。
:param task_names: 每个任务预测目标的名称。
:param device: str,运行设备,如 ``"cpu"`` 或 ``"cuda:0"``。
:param gpus: 多 GPU 时的设备列表,若为 None 则使用 `device`。`gpus[0]` 应与 `device` 对应。
:return: 一个 PyTorch 模型实例。
"""
def __init__(self, dnn_feature_columns, num_experts=3, expert_dnn_hidden_units=(256, 128),
gate_dnn_hidden_units=(64,), tower_dnn_hidden_units=(64,), l2_reg_linear=0.00001,
l2_reg_embedding=0.00001, l2_reg_dnn=0,
init_std=0.0001, seed=1024, dnn_dropout=0, dnn_activation='relu', dnn_use_bn=False,
task_types=('binary', 'binary'), task_names=('ctr', 'ctcvr'), device='cpu', gpus=None):
super(MMOE, self).__init__(linear_feature_columns=[], dnn_feature_columns=dnn_feature_columns,
l2_reg_linear=l2_reg_linear, l2_reg_embedding=l2_reg_embedding, init_std=init_std,
seed=seed, device=device, gpus=gpus)
self.num_tasks = len(task_names)
if self.num_tasks <= 1:
raise ValueError("num_tasks must be greater than 1")
if num_experts <= 1:
raise ValueError("num_experts must be greater than 1")
if len(dnn_feature_columns) == 0:
raise ValueError("dnn_feature_columns is null!")
if len(task_types) != self.num_tasks:
raise ValueError("num_tasks must be equal to the length of task_types")
for task_type in task_types:
if task_type not in ['binary', 'regression']:
raise ValueError("task must be binary or regression, {} is illegal".format(task_type))
self.num_experts = num_experts
self.task_names = task_names
self.input_dim = self.compute_input_dim(dnn_feature_columns)
self.expert_dnn_hidden_units = expert_dnn_hidden_units
self.gate_dnn_hidden_units = gate_dnn_hidden_units
self.tower_dnn_hidden_units = tower_dnn_hidden_units
self.expert_dnn = nn.ModuleList([DNN(self.input_dim, expert_dnn_hidden_units, activation=dnn_activation,
l2_reg=l2_reg_dnn, dropout_rate=dnn_dropout, use_bn=dnn_use_bn,
init_std=init_std, device=device) for _ in range(self.num_experts)])
if len(gate_dnn_hidden_units) > 0:
self.gate_dnn = nn.ModuleList([DNN(self.input_dim, gate_dnn_hidden_units, activation=dnn_activation,
l2_reg=l2_reg_dnn, dropout_rate=dnn_dropout, use_bn=dnn_use_bn,
init_std=init_std, device=device) for _ in range(self.num_tasks)])
self.add_regularization_weight(
filter(lambda x: 'weight' in x[0] and 'bn' not in x[0], self.gate_dnn.named_parameters()),
l2=l2_reg_dnn)
self.gate_dnn_final_layer = nn.ModuleList(
[nn.Linear(gate_dnn_hidden_units[-1] if len(gate_dnn_hidden_units) > 0 else self.input_dim,
self.num_experts, bias=False) for _ in range(self.num_tasks)])
if len(tower_dnn_hidden_units) > 0:
self.tower_dnn = nn.ModuleList(
[DNN(expert_dnn_hidden_units[-1], tower_dnn_hidden_units, activation=dnn_activation,
l2_reg=l2_reg_dnn, dropout_rate=dnn_dropout, use_bn=dnn_use_bn,
init_std=init_std, device=device) for _ in range(self.num_tasks)])
self.add_regularization_weight(
filter(lambda x: 'weight' in x[0] and 'bn' not in x[0], self.tower_dnn.named_parameters()),
l2=l2_reg_dnn)
self.tower_dnn_final_layer = nn.ModuleList([nn.Linear(
tower_dnn_hidden_units[-1] if len(tower_dnn_hidden_units) > 0 else expert_dnn_hidden_units[-1], 1,
bias=False)
for _ in range(self.num_tasks)])
self.out = nn.ModuleList([PredictionLayer(task) for task in task_types])
regularization_modules = [self.expert_dnn, self.gate_dnn_final_layer, self.tower_dnn_final_layer]
for module in regularization_modules:
self.add_regularization_weight(
filter(lambda x: 'weight' in x[0] and 'bn' not in x[0], module.named_parameters()), l2=l2_reg_dnn)
self.to(device)
def forward(self, X):
sparse_embedding_list, dense_value_list = self.input_from_feature_columns(X, self.dnn_feature_columns,
self.embedding_dict)
dnn_input = combined_dnn_input(sparse_embedding_list, dense_value_list)
expert_outs = []
for i in range(self.num_experts):
expert_out = self.expert_dnn[i](dnn_input)
expert_outs.append(expert_out)
expert_outs = torch.stack(expert_outs, 1)
mmoe_outs = []
for i in range(self.num_tasks):
if len(self.gate_dnn_hidden_units) > 0:
gate_dnn_out = self.gate_dnn[i](dnn_input)
gate_dnn_out = self.gate_dnn_final_layer[i](gate_dnn_out)
else:
gate_dnn_out = self.gate_dnn_final_layer[i](dnn_input)
gate_mul_expert = torch.matmul(gate_dnn_out.softmax(1).unsqueeze(1), expert_outs)
mmoe_outs.append(gate_mul_expert.squeeze())
task_outs = []
for i in range(self.num_tasks):
if len(self.tower_dnn_hidden_units) > 0:
tower_dnn_out = self.tower_dnn[i](mmoe_outs[i])
tower_dnn_logit = self.tower_dnn_final_layer[i](tower_dnn_out)
else:
tower_dnn_logit = self.tower_dnn_final_layer[i](mmoe_outs[i])
output = self.out[i](tower_dnn_logit)
task_outs.append(output)
task_outs = torch.cat(task_outs, -1)
return task_outs
|