推荐算法迷思-V1:近期学习有感
近期的工作里,陆陆续续将推荐算法相关的内容,在业务上做了一些尝试。除了对于模型架构层面的探索学习,来自POSO作者赵致辰的推荐算法系列博文带给我很多业务层面的理解。截止至2025年8月2日,我打算当下的一些心得记录在此以便后续学习。
关于精排
精排作为推荐系统里最顶端的环节,是最纯粹的排序模型。而恰恰是因为精排训练的数据来自于自身,很容易出现类似风控算法中的样本分布漂移(实际业务中,只有通过的客户才有后续的还款行为,从而有“是否违约”的标签。而那些被拒绝的用户,我们永远不知道他们是否会违约),正样本越来越少。风控对此的解决方法是拒绝推断,将被拒绝用户“推断”出一个可能的风险标签(即是否会违约),从而扩充训练数据、减少样本偏差,这实际上也是数据增强的一种。
另一方面,精排决定了整个系统的喜好,如果在前面的召回环节做了改进点,而这个改进点不被精排模型认可,那根本不会在结果中体现出效果。
精排的两个问题:
- 正样本不够置信:正样本是用户选择的明确正样本,但负样本却不一定。曝光流量一定程度上决定了这个样本到底有多大的概率成为正样本。有些不够幸运的样本,哪怕事实上足够吸引用户,但未被曝光,那就只能被系统慢慢淘汰。
- 自激:也就是上面提到的样本分布偏移。一言蔽之:自己学自己,那么很有可能在大方向上越走越远。
关于粗排和召回
粗排充当的是精排的助手,为了缓解精排模型的压力,学习的是精排的输出结果,因此使用NDCG作为排序的评估指标。而召回除了为后续模型提供筛选过的基本盘,还需要为后面的模型提供补全:当精排模型因为种种原因,输出不了某一类内容时,就需要一路召回,专门提供相关内容。因此,召回可以是规则,也可以是模型,也可以是双塔相似度计算。
多路召回输出的结果,在融合时需要去重。而分配的顺序也很重要。先部署的召回更有可能会影响整个系统,并且在后续的发展中逐渐占据主导,例如先召回A内容,导致喜欢B内容的客户离开,那么之后哪怕再上线召回B内容的策略,由于客户已经离开,也收获不了正向收益了。
上面这一观点,在精准营销也会有体现,例如被不同策略命中的用户,如果先被外呼渠道营销到,那么他可能在某种层面上就有了“抵抗力”,那么后续再对他进行营销时,就不是一个“新鲜”的客户了,这个策略的转换就会下滑。同样,不同的产品在对同一个用户营销时,谁先营销到,就会占据主动地位,因此运营在营销中的地位举足轻重。
关于策略和模型
写模型并非高级,写规则也并非平凡。各种层面上,规则都必须存在,不光是为了给模型纠偏,还有商业上的考量,也就是广告主的广告位。
关于树模型在精排中的应用
在Kaggle中,树模型非常常见,然而在实际业务中,树模型鲜见在精排模型中。本质原因在于树模型难以处理在线学习中源源不断出现的新ID类特征。尽管树模型可以为未知特征赋予默认值,但在实际业务中,新ID的增长非常迅速。Facebook此前的解决方法是一天一更新模型,但是也与在线学习相悖,并且随着业务的增长,哪怕是树模型也很可能难以在一天内实现收敛。
相反,使用Embedding则可以解决这个问题,对新ID开辟新的Embedding空间,对部署流程几乎没有改动。
下文摘录自赵致辰原文:
目前为止还没有看到树模型和embedding很好地结合的例子,或者准确地说是树模型没什么加embedding的必要和意义。embedding本质上是把低维的ID映射到一个更高的空间中,记录更细致的信息(我个人也有一些相关的经验,比如把所有特征的embedding长度都翻倍,基本上涨幅有大有小,但是从来不会掉点。这表明更大的embedding拥有更多的信息空间),而决策树是按照特征本身的信息划分的。
embedding是很强很暴力,但是embedding需要大量的空间来存,这个时候,树模型就可以大展身手了。既然它不需要embedding,那它就很省空间。一些边边角角的地方,需要模型时都可以考虑用它。不要小看这些边边角角的场合,有些是发挥很大作用的,举两个例子:
判断一个Item处于生命周期中的哪个阶段(简单理解为,一个Item有刚开始起量,稳定膨胀,流量下滑和死亡这么几个阶段,根据这个阶段可以做不同的针对性决策),此时用Item ID做特征显然是没有意义的,而是Item现在总的曝光量,已经投放了多久,每个阶段的曝光,转化等等。
预测一个用户第二天是不是还会来,有各种行为特征,比如在某个类别下观看了多少视频,用户已经用了多长时间,今天的总播放时长是多少等等。
最后归纳:当满足两个条件时,可以优先使用树模型:
- 特征中没有不断新增的ID类特征,类别特征可以穷举,比如年龄,城市等。
- 当输入的特征混有各种各样的类别,数值等等类型的特征时,尤其对于像counter(计数类特征,比如用户在APP上的时间)类很有效果。
关于DNN的范式
DNN在推荐算法工业界已经有了标准化的操作,基本流程是:
- 对于所有特征,通过哈希映射将其转化为ID。
- 每个ID通过嵌入表映射为固定长度的嵌入。
- 嵌入拼接,输入网络。
2019年Facebook发布的DLRM框架如图:
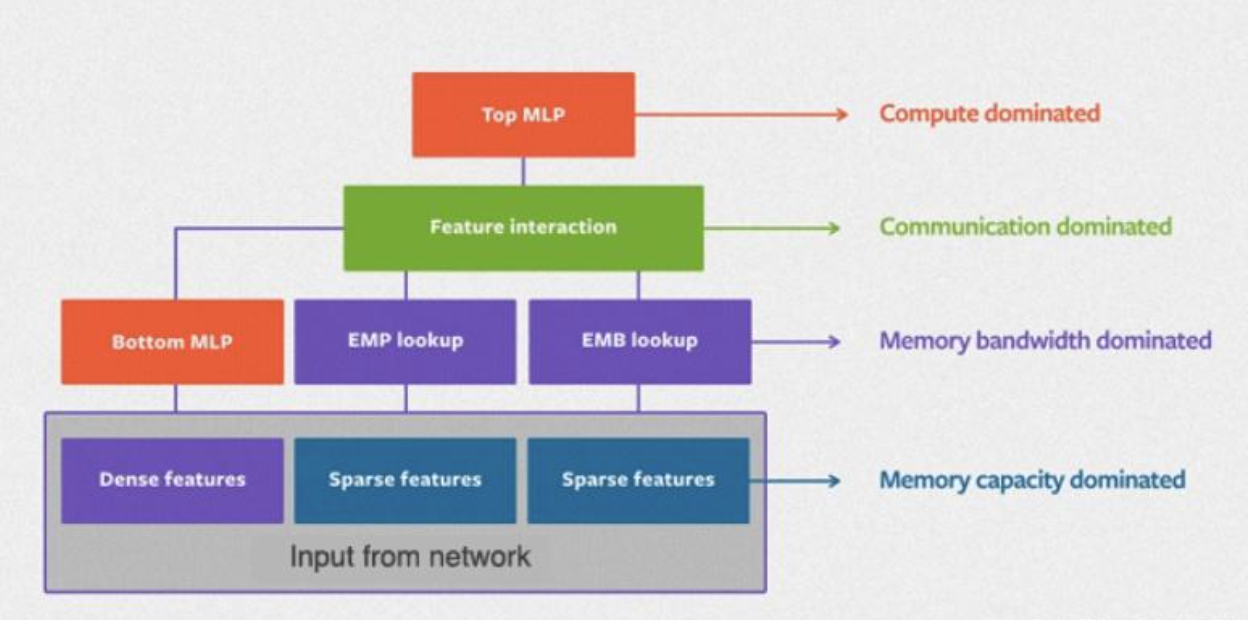
其中的Sparse Features即稀疏特征,为各类ID,Dense Features为数值特征。稀疏特征通过嵌入查表得到嵌入向量,和数值特征拼接后做两两内积,充当特征交叉,最后进入网络。
2025/8/2 于苏州