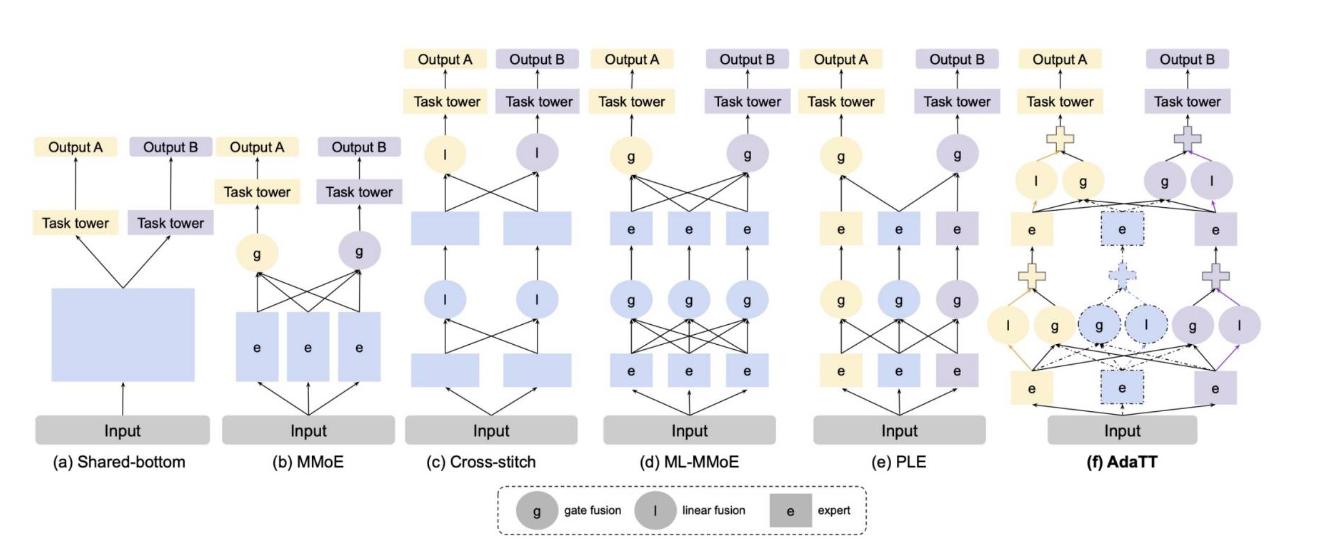
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
| import torch
import torch.nn as nn
class AdaTTSp(nn.Module):
"""
paper title: "AdaTT: Adaptive Task-to-Task Fusion Network for Multitask Learning in Recommendations"
paper link: https://doi.org/10.1145/3580305.3599769
Call Args:
inputs: inputs is a tensor of dimension
[batch_size, self.num_tasks, self.input_dim].
Experts in the same module share the same input.
outputs dimensions: [B, T, D_out]
Example::
AdaTTSp(
input_dim=256,
expert_out_dims=[[128, 128]],
num_tasks=8,
num_task_experts=2,
self_exp_res_connect=True,
)
"""
def __init__(
self,
input_dim: int,
expert_out_dims: List[List[int]],
num_tasks: int,
num_task_experts: int,
self_exp_res_connect: bool = True,
activation: str = "RELU",
) -> None:
super().__init__()
if len(expert_out_dims) == 0:
logger.warning(
"AdaTTSp is noop! size of expert_out_dims which is the number of "
"extraction layers should be at least 1."
)
return
self.num_extraction_layers: int = len(expert_out_dims)
self.num_tasks = num_tasks
self.num_task_experts = num_task_experts
self.total_experts_per_layer: int = num_task_experts * num_tasks
self.self_exp_res_connect = self_exp_res_connect
self.experts = torch.nn.ModuleList()
self.gate_weights = torch.nn.ModuleList()
self_exp_weight_list = []
layer_input_dim = input_dim
for expert_out_dim in expert_out_dims:
self.experts.append(
torch.nn.ModuleList(
[
MLP(layer_input_dim, expert_out_dim, activation)
for i in range(self.total_experts_per_layer)
]
)
)
self.gate_weights.append(
torch.nn.ModuleList(
[
torch.nn.Sequential(
torch.nn.Linear(
layer_input_dim, self.total_experts_per_layer
),
torch.nn.Softmax(dim=-1),
)
for _ in range(num_tasks)
]
)
)
if self_exp_res_connect and num_task_experts > 1:
params = torch.empty(num_tasks, num_task_experts)
scale = sqrt(1.0 / num_task_experts)
torch.nn.init.uniform_(params, a=-scale, b=scale)
self_exp_weight_list.append(torch.nn.Parameter(params))
layer_input_dim = expert_out_dim[-1]
self.self_exp_weights = nn.ParameterList(self_exp_weight_list)
def forward(
self,
inputs: torch.Tensor,
) -> torch.Tensor:
for layer_i in range(self.num_extraction_layers):
experts_out = torch.stack(
[
expert(inputs[:, expert_i // self.num_task_experts, :])
for expert_i, expert in enumerate(self.experts[layer_i])
],
dim=1,
)
gates = torch.stack(
[
gate_weight(
inputs[:, task_i, :]
)
for task_i, gate_weight in enumerate(self.gate_weights[layer_i])
],
dim=1,
)
fused_experts_out = torch.bmm(
gates,
experts_out,
)
if self.self_exp_res_connect:
if self.num_task_experts > 1:
self_exp_weighted = torch.einsum(
"te,bted->btd",
self.self_exp_weights[layer_i],
experts_out.view(
experts_out.size(0),
self.num_tasks,
self.num_task_experts,
-1,
),
)
fused_experts_out = (
fused_experts_out + self_exp_weighted
)
else:
fused_experts_out = fused_experts_out + experts_out
inputs = fused_experts_out
return inputs
|